· 论文复现 · 6 min read
Seeing Text in the Dark:低光任意形状文本检测算法与数据集复现笔记
围绕 ACM MM 2024 论文 Seeing Text in the Dark,本文系统梳理 SCM、DSF、TSR 三个核心模块,并给出可落地的分阶段复现路线。
作者:Tony(基于许程沛等人的 ACM MM 2024 工作)
论文:Seeing Text in the Dark: Algorithm and Benchmark(arXiv:2404.08965)
核心目标:在低光环境下直接进行任意形状场景文本检测(arbitrary-shape scene text detection),避免传统“先低光增强(LLE)再检测”的两阶段误差累积。
为什么这篇工作值得复现?
传统 OCR(如 Tesseract、EasyOCR)在正常光照下表现尚可,但在低光、噪声强、对比度低的真实场景中性能明显下降。该论文提出单阶段(single-stage)方法,直接在低光图像上完成文本定位,并构建了专用低光任意形状文本数据集 LATeD。
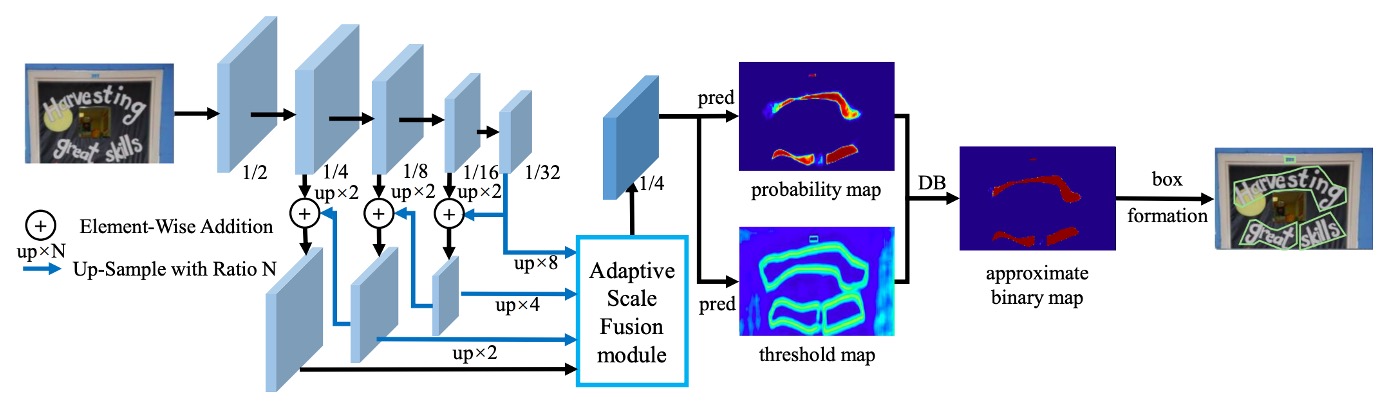
核心创新点(对应论文 Figure 2):
SCM(Spatial-Constrained Learning Module):训练期辅助模块,强化低光文本空间位置与上下文保持。DSF(Dynamic Snake FPN):结合 Dynamic Snake Convolution(DSC)与常规卷积,再通过自注意力门融合,建模细长/弯曲文本拓扑。TSR(Rotated Rectangular Accumulation):bottom-up 塑形流程,使用 Farthest Point Sampling 替代 NMS,并结合形态学操作生成流线型轮廓。
贡献总结:
- 提出无需 LLE 的低光任意形状文本检测单阶段框架。
- 提出
SCM + DSF + TSR三模块协同机制。 - 构建
LATeD(1500 张图像,13,923 个多语言任意形状文本)。 - 在低光数据上达到 SOTA(F1 67.1%),并在正常光数据上保持竞争力。
方法拆解
1. 基础检测器(Base Text Detector)
- Backbone:
ResNet-50 - 输出:
text map、text center region map、旋转矩形几何参数(x, y, h, w, θ) - 损失:分割损失(cross-entropy)+ 高度/角度平滑
L1损失
2. Spatial-Constrained Modeling(SCM,仅训练阶段)
引入空间约束辅助学习模块 Φ:
[ \min_{\theta} L_c(\Psi(u; \theta(\vartheta^))) \quad s.t. \quad \vartheta^ = \arg\min_{\vartheta} L_s(\Phi(u; \vartheta(\theta))) ]
- Spatial Reconstruction Constraint(
L_{sr},L1):重建文本位置掩码,缓解下采样导致的空间信息损失。 - Spatial Semantic Constraint(
L_{ss},L2):约束辅助分支与主干分支的语义一致性。
3. Dynamic Snake FPN(DSF)
并行常规卷积与 DSC,通过自注意力门融合:
[ \mathcal{X}i = \text{concat}(C_i, \mathcal{F}{i-1}) ] [ \mathcal{V} = \text{concat}(\text{Conv}(\mathcal{X}_i), \text{DSC}(\mathcal{X}_i)) ] [ \mathcal{F}_i = \text{softmax}\left(\frac{\sigma(W_Q \cdot \mathcal{V} + b_Q)(\sigma(W_K \cdot \mathcal{V} + b_K))^T}{\sqrt{d_k}}\right) \cdot \mathcal{V} ]
目标是更好地捕捉文本的细长、弯曲、连通拓扑结构。
4. Text Shaping with TSR
- 生成 rotated rectangle 候选。
- 使用 Farthest Point Sampling 过滤中心点(替代 NMS,保留流线型分布)。
- 固定宽度并结合形态学闭运算,得到最终文本轮廓。
5. 总损失函数
[ \mathcal{L}t = \mathcal{L}{\text{seg}} + \mathcal{L}H + \mathcal{L}\theta + \mathcal{L}{ss} + \mathcal{L}{sr} ]
复现准备与环境
推荐起点:
- 使用开源
BPN++或DBNet++作为 base detector(与论文 bottom-up 思路兼容)。 - Dynamic Snake Convolution 参考实现:https://github.com/yaoleiqi/dscnet(ICCV 2023)。
建议环境:
PyTorch 2.x + CUDA- 单卡
RTX 3090 / A6000可跑通(论文使用 A6000) - 常规增强:随机裁剪、缩放、颜色扰动、噪声、翻转、旋转
训练流程(对应论文 5.1):
SynthText预训练 2 epochs(640x640)MLTfine-tune 100 epochsLATeD(或合成低光版)训练 250 epochs,batch size=10,Adam lr=1e-4(每 100 epoch 衰减 0.1)
推荐复现路线(分阶段)
- 跑通基线:
BPN++/DBNet++在 CTW1500/Total-Text 达到 85%+ F1。 - 接入
SCM:重点调试空间重建与语义约束损失。 - 替换 FPN 为
DSF:集成 DSC + 自注意力门。 - 实现
TSR:Farthest Point Sampling + morphological closing。 - 完整消融:逐模块添加,对照论文 Table 4;再做低光实验。
低光数据替代方案(LATeD 暂未公开时):
- 在 CTW1500/Total-Text 上用 gamma 变换 + 噪声 + 降亮度生成合成低光数据。
- 对比四组设置:直接检测、LLE 后检测、fine-tune、fully-trained。
评估指标:Precision / Recall / F1(遵循 CTW1500 多边形评估协议)。
结果复现目标(论文关键数字)
- LATeD:
F1 = 67.1%(显著优于 BPN++ 的 59.5%) - CTW1500:
F1 = 86.2% - Total-Text:
F1 = 88.5%(最高 Recall 86.6%) - 速度:引入模块后 FPS 仍具优势,TSR 替代 NMS 后有加速收益
复现心得
- 优点:模块边界清晰,创新集中在“空间约束 + 拓扑建模”,工程落地价值高。
- 难点:SCM 的辅助损失权重较敏感;低光特征退化导致调参成本偏高。
- 延伸方向:若偏研究可继续做弱监督低光文本检测;若偏工程可尝试蒸馏/量化部署。
代码与数据更新说明:论文宣称将开源代码与 LATeD。若公开仓库未及时发布,建议邮件联系作者获取最新进展。
参考资料:
- arXiv:Seeing Text in the Dark: Algorithm and Benchmark(2404.08965)
- DSCNet:https://github.com/yaoleiqi/dscnet
声明:本文为个人复现笔记,仅供学习交流,所有原创贡献归原论文作者所有。